
데이터베이스 SQL 구문 기초10(INDEX)
인덱스에 대해서
포인터를 활용해서 테이블에 저장된 데이터를 랜덤 액세스하기 위한 목적으로 사용한다.
인덱스 종류
고유 인덱스 : 한 컬럼 기반의 인덱스
결합 인덱스 : 두 컬럼 이상 기반의 인덱스
함수 기반 인덱스 :
CREATE INDEX IDX_EMP_DEPTNO ON EMP(SAL * 12);
rowid: 실제 데이터가 어디에 있는지 확인할 수 있는 번호
이게 인덱스와 관련이 된다.
블럭을 너무 작게 잡으면 전체 데이터를 분할해서 저장해야 함
이렇게 되면 i/o 관련 문제가 발생한다.
너무 크게 블럭을 잡아버리면 메모리 문제가 발생하고
너무 작게 잡으면 i/o 문제가 발생한다. -> 딜레이 발생
그 사이에서 최적의 성능을 잡는게 dba의 일이다.
아무리 sql만 손 대봤자 소용이 없다.
메모리, 인덱스 관련해서 손 보는 게 더 낫다.(dba의 일)
인덱스란??
목차와 비슷한 것이라 생각하면 된다.
일일이 컬럼값을 조회하면서 해당 값을 찾는 것: full scan->성능 저하
따로 지정을 안하면 인덱스는 기본적으로 sys000이런 형식으로 지정
테이블을 만들면 별도의 디스크에 인덱스 정보와 rowid가 생성된다.
아래의 쿼리를 실행해보면 EMP 테이블의 ROWID를 확인해 볼 수 있다.
SELECT ROWID, E.* FROM EMP E
인덱스는 이러한 로우 아이디가 저장된 공간이다.
만약에 인덱스가 없다면 일일이 풀 스캔(FULL SCAN)을 해야 한다.
ORACLE DBMS는 버퍼에 이렇게 조회한 테이블을 쌓아 놨다가 출력하는데, 인덱스를 쓴다는 것은 버퍼에 인덱스가 올라가는 것.
그리고 인덱스에 해당하는 ROWID를 조회 -> 해당 ROWID를 테이블의 ROWID와 비교 ->헤당하는 데이터를 출력하는 과정을 거치는 식으로 데이터에 빠르게 ACCESS한다.
비트리(B-TREE) 인덱스
인덱스의 내부 구조는 B-TREE 형식으로 구성
바이너리 인덱스: 이진트리 구조를 활용한 인덱스
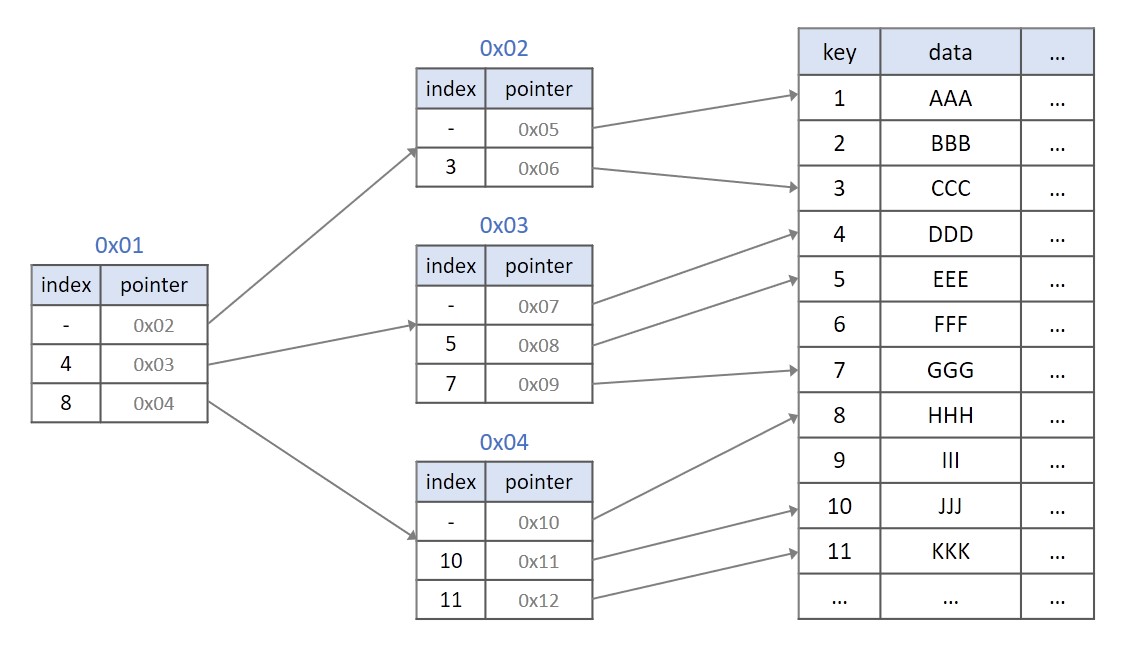
인덱스 생성 시 차순도 설정할 수 있는데, PK의 경우 자동으로 정렬된다.
인덱스를 버퍼에 통으로 올린다.
이 버퍼에서 인덱스 조회를 통해서 로우 ID를 찾고 다시 디스크로 가서
해당하는 블럭만 읽어서 메모리에 올린다.
그리고 결과값이 출력된다.
Q. 만약에 데이터를 잘못 입력했을 경우 인덱스도 거기에 맞춰 수정이 가능할까?
수정이 되는데 그 과정이 번거롭다.
기존의 ROWID는 비활성하고 새롭게 할당해야 한다.
그래서 빈번한 수정이 발생하면 바이너리 트리의 구조가 불균형해지고 난잡해진다.
인덱스 리빌드를 하면 해결되지만, 이 과정에서 데이터 양에 따라 많은 시간이 걸릴 수 있다.
이 동안엔 새로운 데이터가 들어오면 안된다.(고립성)
그래서 DB 업데이트 시에 인덱스가 존재하면 컬럼 값 뿐만 아니라 인덱스도 업데이트 해야 한다.
-> 따라서 빈번한 수정, 삭제가 있는 컬럼에 절대 인덱스를 잡으면 안된다.
인덱스가 없으면 FULLSCAN
따라서
SELECT * FROM EMP WHERE DEPTNO = 20 AND EMPNO = 7876
보다는
SELECT * FROM EMP WHERE EMPNO = 7876 AND DEPTNO = 20
인덱스 만들기
오라클의 객체는 대략적으로 생성할 수 있으면 객체라고 볼 수 있다.
인덱스도 만들 수 있다.
하지만 빈번한 수정이 가해지는 곳은 만들면 안된다.
조회를 빠르게 하기 위한 용도로 사용하기 때문에 분포가 좋은 컬럼에 사용해야 인덱스의 효과가 드러난다.
분포가 좋다 : 군집화가 잘되어있어야 한다.
따라서 남성과 여성으로 나뉜 데이터에서는 분포가 나쁘기 때문에 인덱스 사용을 자제해야 한다.
1. 분포도가 좋은 데이터에 인덱스를 걸어야 한다.(전체의 15퍼센트를 걸러주는 컬럼)
2. 빈번한 수정이 이루어지는 테이블은 인덱스 자제
3. 인덱스 만들 때 컬럼을 섞어서 만들 수도 있다. (복합 인덱스)
복합인덱스 사용 시 순서가 중요하다. (인덱스를 만든 순서대로 WHERE 조건을 써라)
점, 구간(선)
인덱스는 점 데이터 순으로 걸어라
많은 데이터에서 딱 하나 꺼낼 수 있는 것.
자주 사용하는 공통의 WHERE조건은 인덱스를 만든다.
EMPNO = AAA
AND
HIREDATE BETWEEN BBB AND CCC;
여기서 EMPNO 는 점
HIREDATE는 구간
EMPNO에서는 인덱스가 잘 작동하지만, HIREDATE에선 그렇지 않다.
인덱스는 구간에서 잘 작동하지 않는다.
용량만 잡아먹을 뿐이다.
INDEX가 잘 작동하는 순서에 맞게 WHERE 조건을 쓰는 게 좋다.
인덱스 생성
CREATE INDEX IDX_EMP_DEPTNO ON EMP (DEPT);
인덱스 삭제
DROP INDEX IDX_EMP_DEPTNO;
인덱스 리빌드
ALTER REBUILD INDEX IDX_EMP_DEPTNO REBUILD;
인덱스 생성을 통해 메모리 부하를 줄일 수 있다.
결합 인덱스
CREATE INDEX IDX_EMP_DEPTNO ON EMP (DEPT, EMP)
WHERE 순서에 따라 성능 최적화가 달라진다.

댓글남기기